

The Smol Training Playbook
A Comprehensive Guide to Building World-Class Language Models Based on Hugging Face’s Training of SmolLM3


The Mess Behind the Magic
Published research makes LLM training look straightforward: strategic architecture choices, curated datasets, sufficient compute. The results are polished, the ablations clean. Every decision seems obvious in hindsight. But those reports apply a bit of rosy retrospection—they don’t capture the 2am dataloader debugging sessions, the loss spikes that appear from nowhere, or the subtle tensor parallelism bug that quietly sabotages your training for days before anyone notices.

The Smol Training Playbook, released by Hugging Face in October 2025, is different. It chronicles the complete journey of training SmolLM3—a 3-billion parameter multilingual reasoning model trained on 11 trillion tokens using 384 H100 GPUs over nearly 30 days. But unlike typical technical reports, it reads like a drama: promising ablations that don’t translate at scale, a training restart after burning through 1 trillion tokens, and the constant tension between competing objectives.
The core thesis is simple but rarely stated aloud: the messy reality of LLM training—throughput mysteries, tensor parallelism bugs, dataloader issues, loss spikes—is normal. What separates successful projects from expensive failures isn’t avoiding problems. It’s having systems to detect, diagnose, and address them quickly. The Playbook exists to help teams build those systems.
The Democratization of LLM Training
The Playbook’s significance extends beyond its technical content. It embodies a paradigm shift in how AI research knowledge is shared—transforming tacit knowledge accumulated through expensive trial and error into explicit, actionable guidance available to anyone.

Why This Document Exists
The gap between “we trained a model” in a paper and actually training a model has traditionally required either working at a major AI lab or rediscovering every failure mode yourself. The Playbook closes this gap by documenting what papers leave out: the strategic decisions that prevent wasted compute before training begins, the specific failures encountered and how they were diagnosed, ablation results with actual numbers rather than directional claims, and infrastructure decisions that only reveal themselves at scale.
The authors explicitly avoided what they call “a cold list of all we did” in favor of “an organized story through our adventure.” This narrative approach preserves context that raw specifications cannot—the reasoning behind decisions, the alternatives considered, the lessons that only emerge from pain.
The Real Cost of Training
One reality never reflected in published training budgets: ablations and debugging consumed more than half the total project cost.
Main pretraining run (384 GPUs × 30 days): 276,480 GPU-Hours (63%)
Pretraining ablations (192 GPUs × 15 days): 69,120 GPU-Hours (16%)
Mid-training ablations (192 GPUs × 10 days): 46,080 GPU-Hours (11%)
Training reset and debugging: 46,080 GPU-Hours (10%)
Total research overhead: 37%
Organizations planning custom training should budget accordingly: training cost + ablations + a buffer for surprises. The buffer is not optional.
The Training Compass: Should You Even Be Here?
The Playbook begins not with code or architecture, but with an uncomfortable question most teams skip: should you even train your own model?

Machine learning has an obsessive relationship with optimization—loss curves, architectures, throughput. But many failed training projects didn’t fail because of bad hyperparameters or buggy code. They failed because someone decided to train a model they didn’t need. Six months later, after burning through compute budget and team morale, the resulting model sits unused because nobody ever asked why.
The Scenario That Keeps Happening
Someone gets access to a GPU cluster—maybe through a research grant, maybe through spare company capacity—and the thought process goes: “We have 100 H100s for three months. Let’s train a model!” Model size gets picked arbitrarily. Datasets assembled from whatever’s available. Training starts. And then reality arrives.
With Qwen, DeepSeek, Gemma, Llama, Kimi, and others releasing world-class models almost daily, the uncomfortable truth is that most organizations don’t need custom pretraining. If an existing model can handle the task through prompting, don’t train. If fine-tuning solves the problem, don’t pretrain from scratch. The Playbook’s first job is to help teams recognize when they’re in this category.
When Pretraining Actually Makes Sense
Three categories justify the investment:
Domain Specificity: Data involves highly specialized vocabulary or structure that existing models genuinely can’t handle—DNA sequences, complex legal jargon, proprietary codebases. The test: spend a few days building on top of Qwen3 or Gemma3. Can prompting, tool-use, or post-training reach your goals? If not, custom pretraining may be justified.
Deployment Constraints: Models must be tailored to specific hardware, latency requirements, or privacy constraints—LLMs on drones, on-premise systems with FPGAs, edge devices with memory limitations. The constraint must be genuine; most requirements can be met with existing small models.
Safety and Governance: Complete control over training data, model behavior, and update cycles is required. Regulated industries or high-stakes applications where exact training provenance must be proven to regulators.
The Discipline of Ablations
A core principle separates successful LLM labs from failed projects: no architectural change is allowed unless an ablation proves it helps. This systematic empiricism emerges from a hard truth—intuition is almost useless with modern LLMs.

Consider arXiv papers. They represent a vast collection of humanity’s scientific knowledge. Intuitively, training on such rich STEM data should produce superior models. In practice, for small models it actually drags performance down. The reason: while arXiv contains enormous knowledge, it’s highly specialized and written in narrow academic style quite different from the diverse, general text that models learn best from. This finding—impossible to predict without experimentation—illustrates why systematic testing matters more than theoretical reasoning.
Design Principles
Two attributes define successful ablations: speed (experiments should run fast enough to enable frequent iteration) and reliability (strong discriminative power to distinguish between setups early). SmolLM3’s ablations used the full 3B architecture but only 100B tokens instead of the final 11T, validating decisions without paying full computational cost.
Transfer guidance: if something hurts performance at small scale, it’s almost always safe to discard for large scale. But small-scale success requires sufficient training length before concluding with confidence that results will extrapolate.
Beyond Loss Curves
Looking only at training loss isn’t reliable. Models can continue improving on downstream tasks even after pretraining loss has converged. Data mixtures affect loss in ways that don’t correlate with capability—Wikipedia gives lower loss than web pages because next-token prediction is easier, not because it produces more capable models.
Four principles define reliable evaluation tasks: monotonicity (scores improve as models train longer), low noise (identical setups shouldn’t produce wildly different scores), above-random performance, and ranking consistency (if approach A beats B early, this ordering should remain stable).
Architecture Decisions
Despite their differences, recent models like Qwen3, Gemma3, and DeepSeek-V3 share the same foundation—the transformer architecture from 2017. What’s changed are refinements to core components. The Playbook provides ablation data tied to strategic goals.
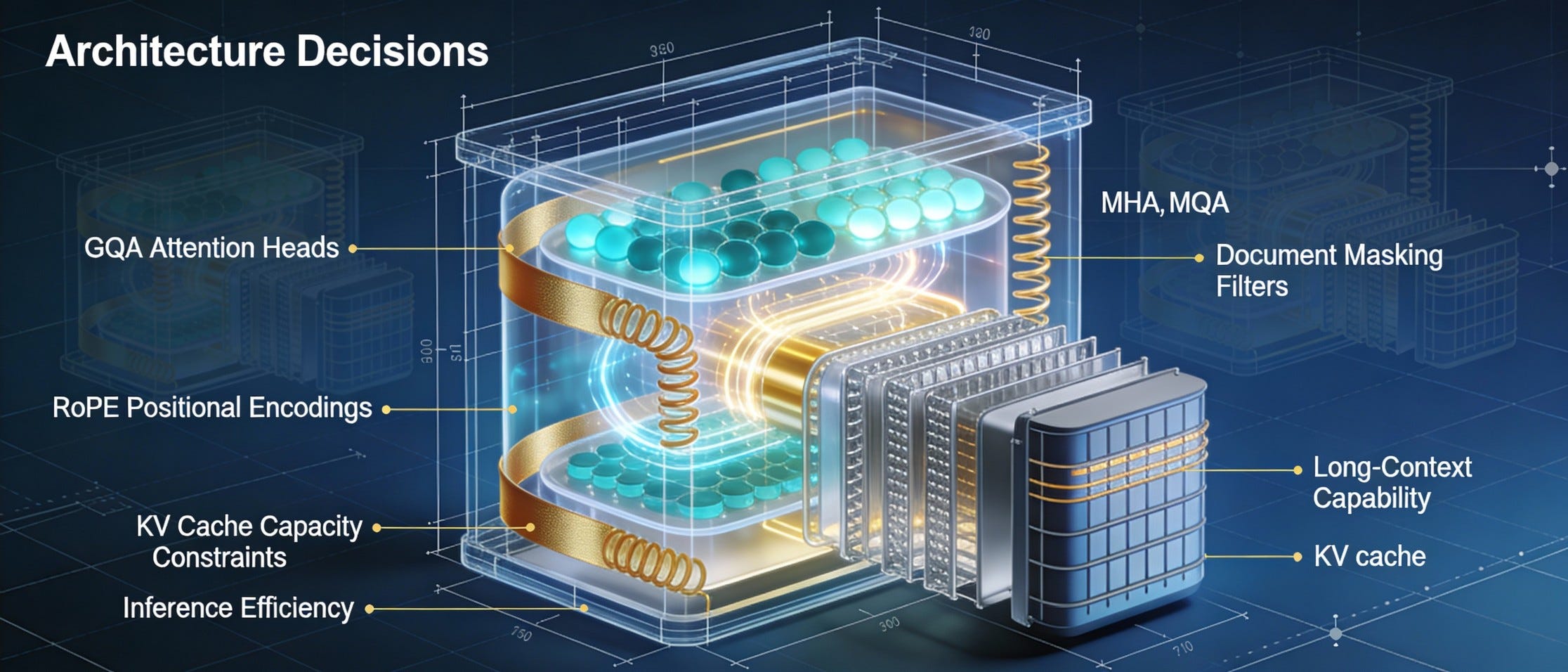
Attention Mechanisms
While feedforward layers dominate compute during pretraining, attention becomes the main bottleneck at inference—especially with long contexts where the KV cache quickly consumes GPU memory.
MHA (Multi-Head): Separate Q/K/V per head; highest capacity but terrible KV cache efficiency. Essentially obsolete for modern long-context inference.
MQA (Multi-Query): Single K/V shared across all heads; dramatic memory reduction. Underperformed significantly on both loss curves and downstream evaluations.
GQA (Grouped Query): K/V shared within groups; middle ground between MHA and MQA. GQA with 4-8 groups matches MHA while dramatically reducing KV cache; adopted for SmolLM3.
MLA (Multi-Latent): Compresses KV into latent space; theoretical efficiency gains. Implementation complexity; not adopted at 3B scale.
Positional Encodings and the Long Context Problem
Transformers have no inherent sense of word order—positional embeddings provide “addresses” in the sequence. RoPE (Rotary Position Embedding) encodes relative distance rather than absolute position, enabling better length generalization. But even RoPE faces challenges as contexts grow toward millions of tokens.
SmolLM2 struggled painfully to extend context length at the end of pretraining. For SmolLM3, the team made architectural choices from day one to avoid repeating that experience: NoPE (alternating layers with and without positional encoding) and intra-document masking were baked in from the start. SmolLM3 extended from 4K to 128K tokens using YaRN interpolation across multiple stages—and it worked.
Document Masking: The Hidden Problem
Analysis revealed that 80-90% of documents in common datasets contain fewer than 2K tokens. With standard causal masking and 4K training sequences, tokens from unrelated documents packed together attend to each other. The Playbook illustrates this vividly: a Python function can attend to a granola bar recipe simply because they happened to be concatenated in the same training sample.
Intra-document masking restricts attention so tokens can only see previous tokens within the same source document. SmolLM3 used it from day one; SmolLM2 added it late and suffered during long-context extension.
Additional Component Decisions
Embeddings: Tied (shared input/output) vs. Untied. Tied: 1.2B tied model matched 1.46B untied. Depth > untying at equivalent budgets.
Experts (MoE): Dense vs. Mixture-of-Experts. Dense: MoE complexity not justified at 3B; edge device memory constraints; 3-month timeline.
Normalization: QK-Norm, Z-Loss, RMSNorm variants. No QK-Norm (hurt long-context); no Z-Loss (overhead without gains); standard pre-norm.
Vocabulary: 49K-128K token range. 49,152 tokens: balanced multilingual coverage with compact embeddings for 3B scale.
Data Curation: The Boring Work That Matters Most
Data curation beats architecture cleverness.
Teams obsess over RoPE vs NoPE, but 80% of model gains come from what the Playbook calls “boring work”—fixing broken PDFs, normalizing code indentation, filtering low-quality samples, balancing domain mixtures. The largest performance improvements consistently come from data quality and mixture optimization, not architectural innovation.

The Unintuitive Nature of Data Mixtures
Simply adding more data from a target domain does not guarantee improved performance on that domain. The interactions between different data sources during training are complex, and the curriculum of training stages matters significantly. What seems like high-quality data doesn’t always yield stronger models. Data mixture ratios require systematic ablation—weighting decisions have significant downstream effects that cannot be predicted from intuition.
SmolLM3’s Three-Stage Curriculum
Stage 1: Foundation (8T tokens): 75-85% English/multilingual web (FineWeb-Edu, DCLM, FineWeb2-HQ); 10-12% code; 3% math.
Stage 2: Specialization (2T tokens): Increased code and math; added Stack-Edu, FineMath4+, MegaMath, Qwen Q&A; web decreased to ~40%.
Stage 3: Refinement (1.1T tokens): Code/math each at 30%; added OpenMathReasoning, OpenCodeReasoning; context extension 4K→64K.
Mid-training (135B tokens): 100B for long context; 35B for reasoning (OpenThoughts3, Llama-Nemotron).
This progressive refinement—starting broad then focusing on high-quality domains—proved more effective than static mixtures or single-stage training on filtered data.
The Training Marathon: When Theory Meets Reality
This is where the Playbook earns its reputation. The training marathon chapter reads like a thriller—problems that never appeared in smaller tests, scale-emergent failures invisible at ablation scale, and the gut-wrenching decision to restart after already burning through 1 trillion tokens.
Mystery #1: The Vanishing Throughput
Training started fast. Then, within hours, speed plummeted. The GPUs were stalling, waiting for something. The culprit: Network Attached Storage couldn’t handle the IOPS required for the 24TB dataset. Under load, it evicted data shards and left GPUs idle.
The fix: Abandon network storage entirely for data loading. Move the entire dataset to local NVMe storage on every compute node. Keep a “spare node” pre-loaded with data to swap in instantly if a GPU fails. Painful, but necessary.
Mystery #2: The Slowdown That Wouldn’t Stop
Even with local storage, throughput showed sharp, periodic drops. The team dug deeper. A bug in the experimental “nanosets” dataloader caused its internal index to grow linearly with training steps. Querying it became slower and slower as training progressed.
The fix: Revert to the battle-tested, simpler dataloader from SmolLM2. The lesson: Do not introduce experimental infrastructure in critical production runs. Still, 1h30 of downtime for the swap... was painful.
Mystery #3: The Bug That Cost a Trillion Tokens
Two days into training. Loss curve looked normal. Evaluations came back. And the 3B model was underperforming its smaller predecessor—SmolLM2-1.7B—at the same training stage.
The team traced it to a subtle bug in Tensor Parallelism initialization. Every GPU in a TP group was starting with identical weights, effectively canceling out the benefits of parallelization. The model was learning, but crippled.
The diagnostic gap: Loss curves showed nothing wrong—training appeared healthy. The bug only surfaced when running downstream evaluations at the first checkpoint. This is the critical lesson: don’t wait for loss anomalies to validate your setup. Run actual capability evaluations early and often.
The decision: Restart. From scratch. After 1 trillion tokens.
That’s not a typo. A trillion tokens of compute—gone. The alternative was worse: continue training a fundamentally broken model and waste even more. The team fixed the initialization, verified the fix with downstream evals, and started over. This is what disciplined training looks like.
The Vibe-Test Imperative
Automated benchmarks showed acceptable results for an early checkpoint. Manual testing revealed the model was completely ignoring system prompts. A bug in the data processing pipeline had stripped them all out.
This failure mode was invisible to standard benchmarks but obvious within seconds of actual conversation. The Playbook advocates “vibe-testing” at every checkpoint—not just at the end of training. Loss curves can be deceiving. Frequent, granular evaluation on downstream tasks is the only way to catch subtle failures early.
Post-Training: From Prediction Engine to Assistant
A pretrained base model is a powerful next-token predictor, but it’s not a helpful assistant. Post-training sculpts this capability into something steerable and reliable.
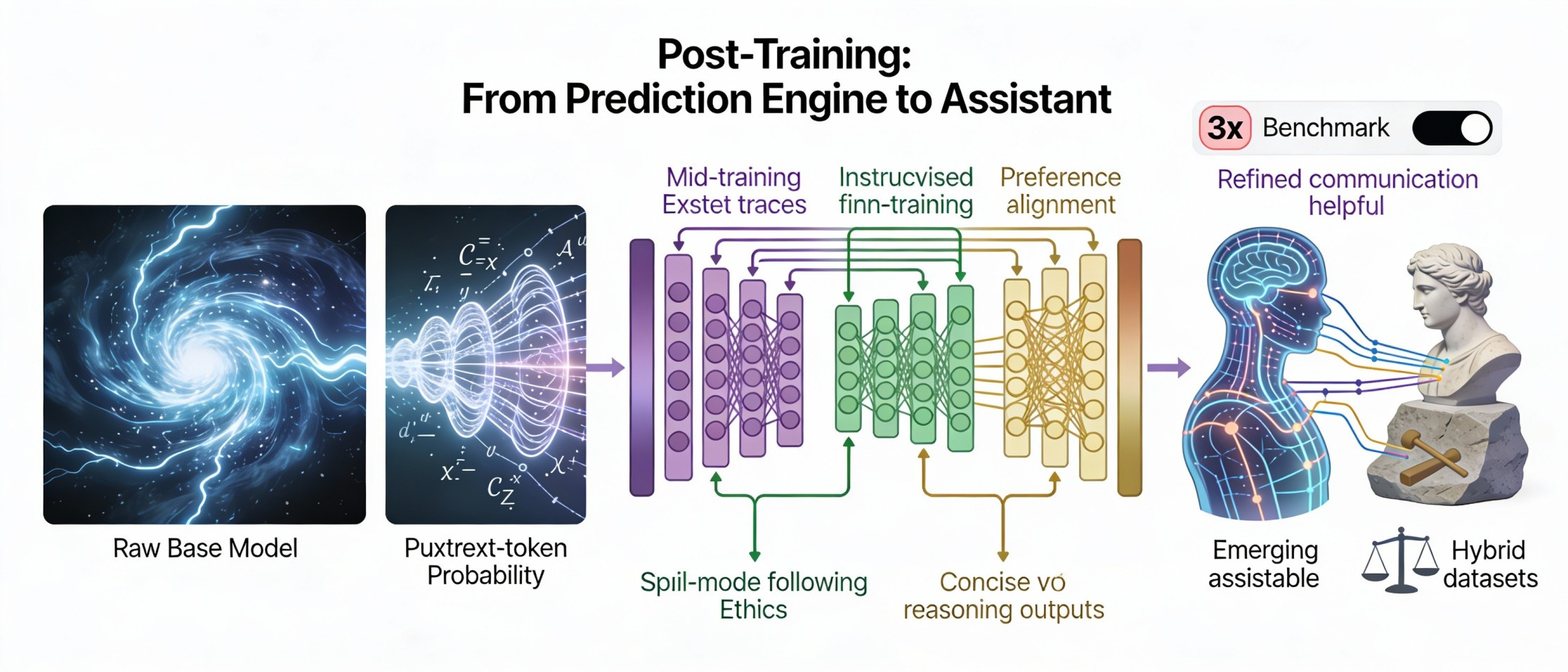
The Pipeline
Mid-Training on Reasoning Traces: Before SFT, continued pretraining on billions of tokens of distilled reasoning traces. This step alone nearly tripled performance on competitive math benchmarks.
Supervised Fine-Tuning (SFT): Training on 1.8B tokens of instruction-following and reasoning datasets (SmolTalk2) using completion-only loss. Data mix balances concise answers with step-by-step thinking traces.
Preference Alignment (DPO): Aligns outputs with human preferences using curated preference datasets. UltraMix was filtered to be 30% smaller than comparable benchmarks while achieving better performance.
Dual-Mode Alignment: SmolLM3 supports toggling between concise mode (direct answers) and reasoning mode (step-by-step thinking with
<think>tags) via system prompt.
Key insight: Hybrid datasets mixing reasoning and non-reasoning instructions prevent “split brain” behavior. Model merging recovered capabilities lost during alignment.
Infrastructure: The Industrial Oven
If pretraining is the cake and post-training the icing, infrastructure is the industrial-grade oven. When it breaks, the project halts. The Playbook devotes significant attention to this reality—not as dry specification, but as hard-won operational knowledge.

SmolLM3’s Setup
Compute: 384 H100 GPUs (48 AWS p5 nodes) for ~30 days, achieving ~30% MFU with 2.36M token global batch size.
Storage: Local RAID-0 NVMe after FSx for Lustre failures; GPUDirect Storage for direct GPU-NVMe access; cold data on S3.
Communication: Intra-node NVLink; inter-node EFA networks; PCIe bottlenecks identified between CPU-GPU.
Operations: Pre-flight checklists (GPU stress tests, Slurm reservations), automated evaluations, frequent checkpoints, auto-resume.
The Hidden Bottlenecks
CPU and storage are often the real bottlenecks, not GPU. Efficient dataloading is just as critical as CUDA optimization. At scale, hardware failure is guaranteed—automated health checks and spare node strategies are mandatory, not optional.
For 3B models, complex 3D parallelism (Pipeline + Tensor + Data) is often overkill. Simple Data Parallelism (FSDP) or minimal Tensor Parallelism is frequently more efficient and less bug-prone. The TP bug that required restarting training? It emerged from unnecessary parallelism complexity.
Key Takeaways
The Playbook’s core message isn’t “here’s how to train a model.” It’s “here’s how to avoid burning millions of dollars by being sloppy.”
Start with whether to train at all. The open-source ecosystem offers powerful alternatives. Custom pretraining requires legitimate domain specificity, deployment constraints, or governance requirements. Most organizations should fine-tune or prompt existing models.
Build on proven baselines. Nearly every successful model starts from existing architectures—Llama, DeepSeek-V3, Qwen—and modifies systematically. Starting fresh means rediscovering every problem yourself.
Ablate everything. No architectural or data change is allowed without empirical validation. Intuition fails with modern LLMs. ArXiv papers hurt small model performance. Theoretical elegance doesn’t predict practical effectiveness.
Data quality dominates. The largest gains come from data curation—fixing broken PDFs, normalizing code, filtering low-quality samples—not from chasing novel architectures. This is the “boring work” that delivers 80% of improvements.
Budget for the real costs. Ablations and debugging can exceed half the main training cost. Scale reveals problems invisible at smaller sizes. Plan for training cost + ablations + surprise buffer. The buffer is not optional.
Vibe-test constantly. Automated benchmarks miss failure modes obvious in seconds of actual use. Manual testing at every checkpoint catches bugs that metrics cannot detect.
Expect the mess. Throughput mysteries, tensor parallelism bugs, dataloader issues, loss spikes—these aren’t signs of failure. What separates successful projects is having systems to detect, diagnose, and fix problems quickly.
Conclusion
The Smol Training Playbook stands as perhaps the most transparent documentation of industrial LLM training published to date. It demystifies the process by showing that even experts at Hugging Face don’t have a perfect recipe—they rely on disciplined empiricism to navigate inherent chaos.
The decision to restart training after 1 trillion tokens. The 2am debugging sessions. The loss spikes that appear from nowhere. The subtle bugs that quietly sabotage everything. These aren’t embarrassing admissions—they’re the reality that polished research papers leave out.
Hugging Face’s training run consumed roughly $1-2M in compute at market rates (384 H100s for 30 days isn’t cheap). But the Playbook’s real gift is making that investment reproducible at a fraction of the cost. A well-resourced startup using spot instances, smaller ablation budgets, and the lessons documented here can now train a competitive 3B model for under $100K. An academic lab can systematically explore architecture hypotheses with $5K in compute. Individual researchers can fine-tune SmolLM3 on consumer GPUs using quantization and LoRA.
The Playbook’s subtitle promises “The Secrets to Building World-Class LLMs.” The real secret is there are no magic tricks—only disciplined iteration, careful measurement, and honest documentation of failures. By sharing not just successful techniques but the complete story of how SmolLM3 came to be, the authors have helped close the gap between research publications and practical implementation. That’s the real contribution: making the next training run a little less chaotic for everyone.

-for the Esteemed Citizen of the Periphery at Foundation’s Edge
This analysis represents personal research and independent industry analysis based solely on publicly available data from providers, vendors, and industry research firms. All Views are entirely my own and based only on public information; they do not represent any employers past or present or any affiliate.Resources
The Playbook: https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook
SmolLM3 Model: https://huggingface.co/HuggingFaceTB/SmolLM3-3B
Training Configs: https://huggingface.co/HuggingFaceTB/training-guide-nanotron-configs
SFT Dataset (SmolTalk2): https://huggingface.co/datasets/HuggingFaceTB/smoltalk