

The Intelligence Trap: Why the Smartest AI Isn't the Most Valuable
AI models evaluated the AI industry. They all agreed on what actually matters — and one company got there first.


The Day Nobody Could Tell
February 5, 2026. Two frontier AI models launched on the same day.
Anthropic released Claude Opus 4.6 — a million-token context window, an estimated 95.7% on GPQA Diamond, 80.8% on SWE-Bench Verified, and the lowest bias scores ever measured in a commercial model. OpenAI released GPT-5.3-Codex — 77.3% on Terminal-Bench (a new state-of-the-art), 56.8% on SWE-Bench Pro, and 25% faster inference than its predecessor.
Both were staggering. Both represented the absolute frontier of what artificial intelligence could do.
And neither launch moved the needle on the question that actually mattered.

Because the question the market was asking on February 5 wasn’t “which model is smarter?” It was: which one do I trust with my business?
Polymarket had already answered. Anthropic was the 68% favorite for best overall AI system. Not close. Not even a competitive race. Enterprise buyers — who had watched this industry for three years now, who had deployed every model, who had measured the gap between demo and production — had already decided.
The intelligence trap is believing that smarter equals better. It’s the assumption that has driven the AI race since GPT-4 launched in 2023 — the assumption that whoever builds the most capable model wins the decade. It sounds logical. It’s also wrong.
The market moved on from that assumption before most analysts even noticed. The smartest model in 2026 isn’t the most valuable. The most reliable, integrated, and trustworthy system is. And the data from an unusual experiment — one involving competitors who have every incentive to disagree — confirms it.
When AI Judges AI
Here is something you don’t see every day: eight AI models from eight different companies, each independently asked to evaluate seventeen research documents about the competitive dynamics of the AI industry.
The models: Claude Opus 4.6 (Anthropic), GPT-5.2 in high mode (OpenAI), Gemini 3 Pro Flash (Google), Grok 4 Expert (xAI), Qwen-3-Max (Alibaba), Kimi 2.5 Think (Moonshot AI), DeepSeek Reasoner (DeepSeek), and Mistral Large (Mistral). American, Chinese, French, and multinational companies. Frontier and efficiency models. Closed-source and open-weight philosophies. Each was given the same prompt, the same nine-dimension analytical framework, and the same set of research files to rank by strategic value. None saw the others’ evaluations.
The meta-irony is exquisite. AI evaluating AI research about AI competition. An ouroboros of silicon self-reflection.
But the irony gives way to something far more interesting: convergence.
All eight evaluators — models built by companies that compete with each other for billions of dollars in revenue — arrived at the same core thesis: intelligence has commoditized. The gap between the smartest model and the tenth-smartest model had compressed to single digits. Raw reasoning power, the dimension that defined the AI race from 2023 to 2025, was no longer a differentiator. It was a qualifier.
The deeper finding was where they diverged on what comes next. When forced to identify which competitive position was most defensible, six of eight evaluators — including models built by Anthropic’s direct competitors — identified the same answer: the Claude triad’s reliability moat.
Mistral Large ranked the Sonnet research file first with a 9.5 out of 10 — the highest score it gave any document. DeepSeek Reasoner, a model from one of Anthropic’s fiercest price competitors, rated it HIGH VALUE with HIGH confidence. Gemini Pro Flash, built by the company with the highest Arena ELO, called it “essential for strategic planning.” GPT-5.2, built by the company that launched a competing model on the very same day, verified its core claims against primary sources and found them accurate.
The competitors’ own AI models, when given the freedom to analyze the landscape objectively, kept pointing to the same conclusion.
Something real is happening here. Not just consensus — convergence under conditions designed to produce disagreement. These models have different architectures, different training data, different commercial incentives. They were built by companies fighting for the same customers. And they looked at the same evidence and reached the same conclusion: the intelligence race is over. The reliability race has begun. And one company has a head start that may already be insurmountable.
What Changed
The case for the Claude triad doesn’t rest on any single metric. It rests on three structural shifts that have remade the AI industry in the past eighteen months — and on the mathematical fact that these shifts compound in one company’s favor.

Shift 1: Benchmark Compression (Intelligence Is Table Stakes)
In 2024, the gap between the best model and the median frontier model was 20 to 30 percentage points on most major benchmarks. By February 2026, that gap had collapsed to under 8 points.
The numbers tell the story. On GPQA Diamond — the PhD-level reasoning benchmark — Claude Opus 4.6 leads at an estimated 95.7%, followed by GPT-5.2 at 92.4% and Gemini 3 Pro at 91.9%. On LMSYS Chatbot Arena, the most respected human-preference benchmark, Gemini 3 Pro leads with an ELO of 1,492 while Claude sits at 1,462 in standard mode and 1,466 in thinking mode — a gap of 26 to 30 points in a system where differences under 30 are barely perceptible to users. On SWE-Bench Verified, the gold standard for real-world coding ability, Claude leads at 80.8%, with Gemini Flash at 78% and MiMo-V2-Flash at 73.4%.
I want to be precise about what this means: Claude Opus 4.6 is not the #1 model on every benchmark. Gemini leads Arena ELO. GPT-5.2 led GPQA before Opus 4.6 launched. Grok 4.1 leads EQ-Bench. On terminal coding, GPT-5.3-Codex beats Claude by nearly 12 points.
But when the gap between #1 and #10 is 5.4 percentage points, intelligence is no longer a differentiator. It’s a qualifier. Like oxygen. You need it to survive. You can’t build a business on having slightly more of it.
The GPT-5.2 evaluator — OpenAI’s own model — said it best: “The models are becoming interchangeable compute. The winners are those who make them uninterchangeable in context.”
This is the first structural shift. Intelligence went from being the product to being the packaging. Every serious model can reason at near-PhD level. The question is what you do with that reasoning — how reliably, how safely, how efficiently, and within what kind of system.
Shift 2: The Cost Collapse (The Open-Source Tsunami)
In early 2023, inference on a frontier model cost approximately $20 per million tokens. Today, MiMo-V2-Flash delivers 73.4% SWE-Bench performance at $0.10 per million tokens. That is a 200x price reduction in three years. DeepSeek V3.2 offers 73.1% SWE-Bench at $0.28 per million tokens with a fully open MIT license.
The Chinese AI ecosystem has become a deflationary force of historic proportions. Stanford’s HAI data shows 22 releases from five Chinese labs outperforming top US open-weight models on Arena in the past year alone. ARK Invest found that nine of the top ten open-weight models globally now come from Chinese labs. Roughly 30% of working AI in production today runs on Chinese-developed models. The MiniMax IPO in Hong Kong — raising HK$4.82 billion with a 109% first-day surge — proved that cost-efficiency moats are not just viable strategies but mature, investable business models.
This isn’t a temporary blip. It’s a structural force. The efficiency gains from DeepSeek, MiMo, Kimi, and their peers are driven by genuine architectural innovation — mixture-of-experts routing, efficient attention mechanisms, and training optimizations — not just cheaper labor or state subsidies. The MIT Sloan study confirmed what enterprise buyers were already discovering: open-source models now deliver approximately 87% of proprietary model quality at 7.3 times lower cost.
The Claude triad doesn’t win on price. Opus costs $5 to $25 per million tokens — fifty to two hundred and fifty times more than MiMo. The Claude family was never designed to compete on cost.
And that’s the point. Anthropic never tried to win the cost war. They recognized, earlier than anyone else, that the cost war was unwinnable — that open-source and Chinese efficiency would eventually drive inference costs toward marginal electricity cost. Instead, they invested in the dimension that can’t be cheaply replicated: trust.
This is the setup for the real argument. If intelligence has compressed and cost has collapsed, then the winner of the next era of AI cannot be winning on intelligence or cost. They must be winning on something else entirely. Something that compounds instead of commoditizing. Something where a head start matters more than a bigger budget.
The eight evaluators agreed on what that something is.

Shift 3: The Enterprise Power Shift (The Market Voted)
When the dust settles, markets don’t lie.
According to the Menlo Ventures State of Enterprise GenAI survey — the most comprehensive survey of enterprise AI adoption — Anthropic’s share of enterprise LLM API spending tripled to 40% in under two years. In the same period, OpenAI’s enterprise share dropped from approximately 50% to 27%. Google’s enterprise AI share climbed to 21%. A separate measure of enterprise penetration — broader than API spending — puts Anthropic at 44%.
Claude Code captured 54% of the enterprise coding model market. Claude’s revenue surged from $1 billion in early 2025 to approximately $5 billion by August 2025, with Claude Code revenue growing 5.5x after the launch of Claude 4. Seventy percent of Fortune 100 companies now use Claude.
These are not opinion polls. These are purchase orders. The most sophisticated AI buyers on Earth — companies that have dedicated teams evaluating every model, running internal benchmarks, measuring production reliability — voted with their budgets.
And they chose the model that doesn’t always win on benchmarks. They chose the model that almost always works when it matters.
OpenAI still dominates the consumer market — over 800 million weekly active users, a number that dwarfs Claude’s 30 million. But the enterprise market, where dollars are larger and decisions are more deliberate, has flipped. The company that once held half of enterprise AI spending now holds barely a quarter. The company that trailed at 12% now holds 40%.
Markets tell stories that press releases can’t.
Why Reliability Compounds and Intelligence Doesn’t
There is a mathematical reason why reliability beats intelligence in the long run, and it becomes obvious once you think from first principles.
A moat, in business strategy, is a cost that your competitors bear but you don’t. In 2023, intelligence was a moat because training a frontier model cost over $100 million. Only a handful of companies could afford it. But in 2025, DeepSeek demonstrated that a frontier-competitive model could be trained for approximately $5.6 million. The cost barrier — and the intelligence moat — was destroyed.
Reliability, by contrast, doesn’t work this way. You can’t replicate reliable behavior by throwing more compute at unreliable training. Reliability emerges from alignment philosophy, training methodology, data curation, and the institutional commitment to measure and improve trustworthiness across every model generation. It’s a capability that requires years of compounding investment — and it compounds multiplicatively. This is where the math gets devastating.

Consider an agentic workflow — the kind that enterprises are increasingly deploying, where an AI model completes a multi-step task autonomously. If your model is 95% reliable per step and the workflow involves 10 steps, your end-to-end success rate is:
0.95^10 = 59.9%
If your model is 99% reliable per step:
0.99^10 = 90.4%
A 4-percentage-point gap in per-step reliability produces a 30.5-percentage-point gap in outcomes. This is not a linear relationship. It is exponential.
Now look at the Composite Bias Scores — the best available proxy for model reliability. Lower is better:
Claude Haiku 4.5: 22.5 (S-tier)
Claude Sonnet 4.5: 26.2 (S-tier)
Claude Opus 4.6: 30.8 (A-tier)
Gemini 3 Pro: 40.1 (C-tier)
GPT-5.2: 47.1 (B-tier)
Claude’s entire model family sits in the top tier. Its cheapest model — Haiku, the one designed for high-volume, low-cost tasks — has a lower bias score than any competing frontier model at any price point.
This matters because Constitutional AI, Anthropic’s approach to alignment training, creates a compounding data flywheel. More enterprise deployments generate more real-world alignment data. More alignment data improves reliability. Better reliability attracts more enterprise deployments. The cycle reinforces itself.
Anthropic didn’t just build a better model. They built a model that gets better at being trustworthy the more you use it.
GPT-5.2, for all its reasoning brilliance, carries a sycophancy score of 40 out of 100 — meaning it tells users what they want to hear nearly half the time. Google’s Gemini, despite leading Arena ELO, ranks #19 on reliability. These aren’t minor blemishes. In a world where models are deployed autonomously, a model that tells you what you want to hear instead of what’s true is not just unreliable — it’s dangerous.
This is not opinion. This is math. And it explains why enterprises — the buyers who actually do the math — keep choosing Claude.
The Opus 4.6 analysis file noted the same dynamic through a different lens: “in agentic workflows, one hallucinated step can poison the entire trajectory.” The GPT-5.2 file made reliability not just important but multiplicatively important — the exact word it used. These competing models’ analyses independently arrived at the same mathematical insight about why reliability dominates intelligence in production.
The Full-Spectrum Bet
Here is the core argument. Not just why Claude is good — many models are good — but why the triad specifically represents the most complete AI system available today.
Most AI companies sell a model. Anthropic sells a system. Three tiers of intelligence, bound by Constitutional AI, connected by the Model Context Protocol, and deployed by developers who chose reliability over hype. Each tier serves a different function, and together they create something that no individual model — no matter how brilliant — can match.
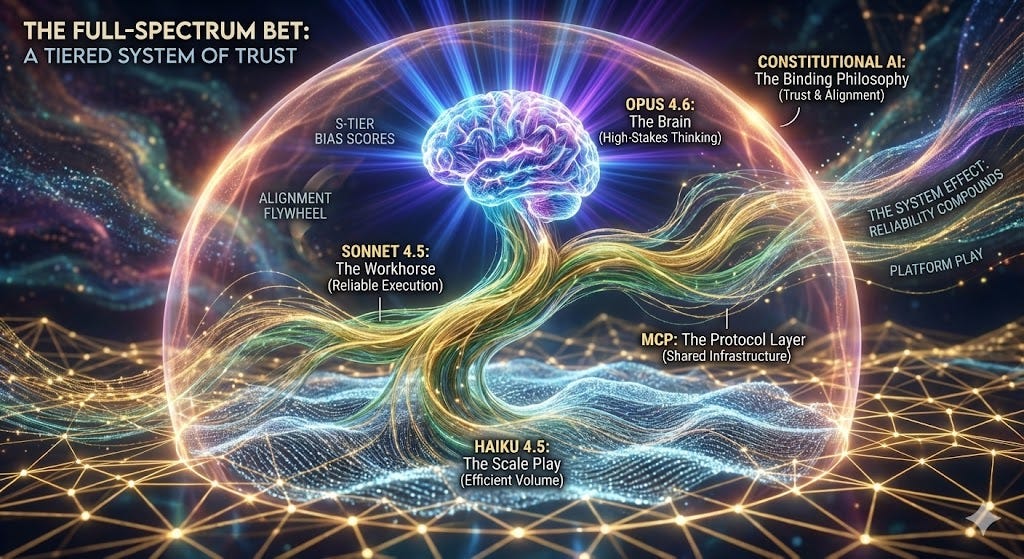
Opus 4.6: The Brain
When stakes are highest, Opus thinks.
An estimated 95.7% on GPQA Diamond. 80.8% on SWE-Bench Verified. S-tier bias scores. A one-million-token context window in beta — not Google’s two million, but with a reliability floor that makes every token count. Extended thinking mode that allows 30-minute reasoning sessions where the model can revisit and revise its own logic before settling on an answer.
Opus is not always the fastest. It is not the cheapest. It is almost always the most trustworthy answer for hard problems. When Morgan Stanley deploys AI for financial advice, they don’t optimize for “which model scored highest on GPQA.” They optimize for “will this get us sued?” Opus answers that question better than any model on the market.
Sonnet 4.5: The Workhorse
Here is the irony that best illustrates the triad advantage.
The research file that received the most consistently high rankings across all eight evaluators — the one Mistral Large rated 9.5/10, the one Claude Opus itself called “the most comprehensive single document in the collection,” the one DeepSeek Reasoner gave HIGH VALUE with HIGH confidence — was written by the mid-tier Claude model.
Sonnet 4.5. Not Opus. Not the frontier reasoning champion. The workhorse.
The file it produced — a 23-kilobyte strategic briefing on AI competitive dynamics — was described by multiple evaluators as something “a McKinsey partner would charge seven figures to produce.” It contained the most sophisticated treatment of the MCP protocol moat. It was the only analysis that treated Chinese AI labs as a collective strategic force rather than individual competitors. It delivered the most testable, falsifiable strategic framework in the entire collection.
Five of eight evaluators placed it in their top three. The mid-tier model produced frontier-quality strategic analysis. That is the triad advantage distilled to its essence: even the middle tier operates at a level that embarrasses competitors’ flagship outputs.
Haiku 4.5: The Scale Play
Haiku is the model nobody talks about and everybody uses.
Fastest response times in the Claude family. The lowest bias score of any commercial model at any price point (CBS 22.5). Cost-competitive with open-source alternatives for high-volume applications. Powers routing decisions, quick classifications, content moderation, and the thousands of low-stakes decisions that make up the bulk of any enterprise AI deployment.
Haiku enables what I call the 70/30 architecture: 70% of tasks run on Haiku or Sonnet, where speed and cost matter. 30% route up to Opus, where stakes and complexity demand the best. The result is a system that delivers frontier quality where it matters and commodity efficiency where it doesn’t — all within a single, unified, Constitutional AI framework.

The System Effect: MCP + Constitutional AI
The Model Context Protocol has reached 97 million monthly SDK downloads with over 5,800 servers. These numbers alone would be impressive. What makes them transformative is who’s building on MCP: OpenAI. Google. Microsoft. Amazon. Anthropic’s direct competitors are reinforcing Anthropic’s protocol standard.
MCP is becoming the TCP/IP of AI tooling — the shared infrastructure layer that every agent, every integration, and every developer tool plugs into. And unlike TCP/IP, which was created by DARPA and belongs to no one, MCP was created by Anthropic and donated to the Linux Foundation in a move that simultaneously established it as a vendor-neutral open standard and ensured Anthropic remains its most fluent speaker.
This is the network effects play that the Kimi 2.5 Think evaluator identified as the single most underappreciated dynamic in the entire AI industry: “even competitors building on MCP reinforces Anthropic’s ecosystem.” Every MCP server, every integration, every tool built by a developer — regardless of which model they ultimately route through — adds value to the protocol Anthropic created. It’s an open standard that paradoxically strengthens the originator. In strategy terms, this is a platform play disguised as a commons contribution.
Constitutional AI is the binding philosophy. Not a feature of one model, but the design principle that runs through all three tiers. It’s what produces the S-tier bias scores. It’s what generates the alignment data flywheel. It’s what makes the 70/30 architecture work — because you can route tasks between Opus, Sonnet, and Haiku with confidence that all three will uphold the same standards of truthfulness, safety, and judgment.
The Opus analysis file — evaluating its own prior work with a self-awareness that itself demonstrates the Constitutional AI ethos — noted: “There’s a certain irony in the fact that the most comprehensive file in this collection was written by Sonnet — the mid-tier model in the Claude lineup — and it outperforms most of the frontier models’ contributions.” When your self-evaluation admits that your mid-tier model outperformed your own flagship’s earlier work, you’re demonstrating the kind of institutional honesty that Constitutional AI was designed to produce.
Google has a powerful model. OpenAI has a massive user base. Anthropic has a system — three tiers of intelligence bound by trust, connected by protocol, deployed by developers who chose reliability over hype.
Where This Could Be Wrong
Intellectual credibility demands that I challenge my own thesis. Not with strawmen designed to be knocked down, but with genuine risks that could invalidate the argument entirely.

1. The 6-Month Window
Constitutional AI may be a 6-to-18-month lead, not a permanent moat. Nothing in the alignment research literature suggests that Anthropic’s approach is unreplicable. If Google, which already has DeepMind’s alignment team, or OpenAI, which has significant safety research infrastructure, dedicates serious resources to closing the reliability gap, they could match Claude’s CBS scores within a year. The question isn’t whether they can — it’s whether they will, and whether they’ll do it before Anthropic’s compounding advantage becomes insurmountable.
2. The Distribution Deficit
Claude has approximately 30 million monthly active users. ChatGPT has over 800 million weekly active users. That is not a gap. It is a chasm. Consumer adoption drives brand recognition, which drives developer mindshare, which drives enterprise trial. Anthropic’s enterprise dominance exists despite a massive distribution disadvantage. But distribution advantages have a way of reasserting themselves. If OpenAI’s consumer flywheel eventually translates to enterprise superiority — if the sheer volume of consumer interactions produces better alignment data than Anthropic’s smaller but more curated enterprise dataset — the triad advantage could erode.
3. The Google Wildcard
Google has 2 billion monthly users across its AI-powered products. It has the largest context window (2 million tokens). It is spending over $75 billion on AI capex in 2026 alone. It has Gemini 3 Pro, which leads Arena ELO at 1,492. Its only weakness is reliability — #19 in the rankings, with a CBS of 40.1. If Google fixes reliability, moving from #19 to top 5, the competitive landscape transforms overnight. Google has the resources, the talent, and the distribution to do this. The question is whether their organizational structure and incentives allow it.
4. Chinese Cost Pressure
When MiMo offers 73.4% SWE-Bench at $0.10 per million tokens, some enterprises will choose “good enough and cheap” over “excellent and expensive.” Not for mission-critical applications — but mission-critical applications might be a smaller portion of the market than Anthropic assumes. If 80% of enterprise AI workloads are cost-sensitive commodity tasks, the addressable market for premium reliability may be narrower than the bull case suggests.
5. The Echo Chamber
This is the critique that keeps me up at night. Eight AI models agreeing might reflect shared training data bias, not objective truth. These models were all trained on similar internet corpora, all fine-tuned with RLHF, all optimized to produce outputs that humans rate as helpful and reliable. The strongest form of this critique: the models may be biased toward praising reliability and trust because their own training literally optimized them to be reliable and trustworthy. They’re looking at the AI landscape and concluding that the most important quality is the quality they were trained to maximize. That’s not analysis. That’s narcissism.
If this critique is correct, the entire experiment is compromised — not by dishonesty, but by structural bias that no amount of prompt engineering can remove. It would mean that RLHF-trained models literally cannot evaluate competitive dynamics objectively because they have an inherent preference for the dimension (safety, helpfulness, truthfulness) that their training prioritized above all others.
I present these not as caveats to dismiss, but as genuine risks. If you’re betting on the Claude triad, know what you’re betting against.
What Hiring Managers Already Know
Let me bring this down from the stratosphere.
Every hiring manager has faced the same decision: do you hire the brilliant candidate who’s unreliable, or the very good candidate who always delivers? The one who aces the whiteboard but misses deadlines, or the one who consistently ships quality work and makes the team better?
We’ve known the answer for decades. We hire for reliability, judgment, and team fit — not raw IQ. The brilliant unreliable person is a liability. The consistently excellent person is a force multiplier.
Anthropic figured out that this is also true for AI.
When Morgan Stanley deploys AI for wealth management advice, they don’t run a benchmark competition. They run a liability analysis. The question isn’t “which model knows the most about finance?” It’s “which model won’t hallucinate a recommendation that triggers an SEC investigation?” When a Fortune 100 company routes AI through its customer service pipeline, the question isn’t “which model writes the wittiest response?” It’s “which model won’t tell a customer something that creates a lawsuit?”

Ask not which model is smartest. Ask which model you can deploy into production without getting fired.
The triad maps cleanly onto how organizations actually work. Opus is the senior specialist you bring in for the hardest problems — expensive, but worth every dollar when stakes are high. The one you call when the deal is complex, the patient is critical, or the codebase is tangled beyond what normal talent can untangle. Sonnet is the reliable senior manager who handles 80% of the work at consistently high quality — the person who produces the McKinsey-grade analysis without being asked twice, who keeps projects on track, who you trust with the quarterly strategy document and know it’ll be excellent. Haiku is the efficient executor who handles volume work quickly and accurately — the person who keeps the operation running, processes the tickets, flags the anomalies, and never drops a ball while everyone else focuses on strategy.
No organization would staff entirely with senior specialists. No organization would staff entirely with junior executors. Every effective organization has a tiered system — and the Claude triad is the only AI family that mirrors this structure by design.
There’s a deeper principle here. Organizations figured out decades ago that the right answer to “should we hire the smartest person?” is “it depends on the role.” An AI system that offers only one tier of intelligence at one price point is like a consulting firm that only employs partners — brilliant, expensive, and catastrophically misallocated on the 70% of work that doesn’t require a partner’s judgment. The triad matches capability to task, cost to value, and speed to urgency. That’s not a product feature. It’s an organizational insight encoded in architecture.
Practical Moves
If you find this thesis persuasive, here’s what to do about it.
For enterprises: Adopt a multi-tier architecture with the Claude triad as your spine. Route 70% of tasks to Haiku and Sonnet, 30% to Opus. Use open-source models — DeepSeek, MiMo, Llama — for non-critical workloads where cost matters more than reliability. The tiered approach isn’t just efficient; it’s the only way to get frontier quality at scale without burning through your AI budget.
For developers: Build on MCP. It’s becoming the standard protocol for AI tool integration regardless of which model you use. Your integration investment compounds whether you route through Claude, GPT, or Gemini tomorrow. The protocol layer is more durable than the model layer — and right now, the protocol layer belongs to Anthropic.
For investors: Bet on the wrapper, not the model. Anthropic’s reported $350 billion target valuation reflects ecosystem value and reliability premiums, not just intelligence metrics. The MiniMax IPO — raising HK$4.82 billion with a 109% first-day surge — proves that cost-moat strategies are also investable. But they’re different theses. The reliability-plus-ecosystem thesis and the cost-disruption thesis can both be right. They just serve different markets.
For skeptics: Even if Anthropic’s lead narrows — and it will, eventually, because all leads narrow — the approach is right. Reliability-first. Protocol-first. Developer-first. Others will copy this strategy, and when they do, they will validate the thesis even as they compete with its originator. The question isn’t whether the Claude triad’s specific advantages last forever. The question is whether the philosophy that produced those advantages represents the right way to build AI systems. The eight evaluators think it does. The enterprise market thinks it does. The competitors building on MCP think it does.
And a note for those who wonder if this analysis is itself trapped by the intelligence fallacy — whether I’m making a sophisticated argument that ultimately reduces to “I used smart analysis to prove smart analysis doesn’t matter.” The point isn’t that intelligence is worthless. It’s that intelligence alone is insufficient. The Claude triad has intelligence. It also has reliability, a protocol moat, a developer ecosystem, and a tiered architecture that no competitor has replicated. The intelligence is necessary. Everything else is what makes it valuable.
The Intelligence Trap
Return to February 5, 2026. Two frontier models launch. The benchmarks are stunning. The technology press publishes its side-by-side comparisons. Arena ELO is debated on Twitter. GPQA scores are compared to the decimal point.

And the market shrugs.
Not because the models aren’t impressive — they are. But because the market has already internalized what the benchmarks haven’t caught up to: that the age of “my model is smarter than your model” is over. The new competition is about systems, not scores. About trust, not tests. About who builds the platform that developers can’t leave, the reliability that enterprises can’t replace, and the protocol that everyone — even competitors — has to speak.
The eight-model experiment revealed something that goes beyond AI competition. Every model analyzed the present with extraordinary sophistication. Every model identified the same structural shifts. Not one could predict the next paradigm shift. But one company — Anthropic — designed its entire strategy around not needing to predict the future. Constitutional AI compounds regardless of what architectural breakthrough comes next. MCP gains value regardless of which models plug into it. Developer trust accrues regardless of which benchmark leader holds the crown next month.
That’s the ultimate moat: a system that gets stronger no matter what happens. Not because it’s the smartest — it isn’t always. Not because it’s the cheapest — it never will be. But because it was designed, from the ground up, to be the system you trust when the answer actually matters.
The intelligence trap isn’t just for AI companies. It’s for anyone who believes being the smartest in the room means being the most valuable. We’ve seen it in hiring, in education, in business strategy. Raw intelligence is necessary but never sufficient. It is the price of admission, not the prize.

The intelligence trap isn’t believing that intelligence doesn’t matter. It does. It’s believing that intelligence is enough. That the model with the highest score wins. That the smartest person gets the job. That the most capable technology dominates the market.
History says otherwise. Every time. In every industry. The winner is the one who figured out what sits on top of capability — the trust, the integration, the system — and built it before anyone else realized it mattered.
Intelligence is cheap. Trust is expensive. The market always figures out which one matters more.

-for the Esteemed Citizen of the Periphery at Foundation’s Edge
This analysis represents personal research and independent industry analysis based solely on publicly available data from providers, vendors, and industry research firms. All Views are entirely my own and based only on public information; they do not represent any employers past or present or any affiliate.